Last updated on
这是一篇来自快手的文章,主要讲了两件事,第一件事是如何对观看时长进行建模,第二件事是如何对连续特征进行分桶。
如何对观看时长建模?
快手(KWai)的短视频观看时长分布和我们的直播场景的观看时长有着类似的趋势,即数据极其不均衡,呈现典型的长尾分布。

通常预测观看时长有几种方法
- Regression
- Weighted Logistic Regression
- Duration-Deconfounded Quantile
- Ordinal Regression
- Tree based Progressive Regression
能否提出一个更简单的训练任务来预测观看时长?
这篇文章提出的方案是,使用多个分类任务近似去拟合回归任务。具体的做法和我们处理连续特征的方案类似,把观看时长离散化分成多个桶,对于每个桶进行预测是否落到这个桶里。

需要注意的是这里的离散化方法并没有使用 onehot,而是预测大于某一时间阈值的概率,即
ym=(y>=tm)
推导
分类任务变成如下形式
ϕ^m(xi;Θm)=P(y>tm∣xi),1<=i<=N
恢复公式推导
E(y∣xi)=∫t=0tmtP(y=t∣xi)dt=∫t=0tmP(y>t∣xi)dt≈m=1∑MP(y>t∣xi)(tm−tm−1)
这里重点看下第二步
P(y>t)P(y=t)=1−F(t)=R(t)=F′(t)=−R′(t)
可以带入式 1
===∫t=0tmtP(y=t∣xi)dt−∫t=0tmtR′(t)dt−tR(t)∣0tm+∫t=0tmt′∗R(t)dt∫t=0tmP(y>t∣xi)dt
结合就能得到
y^=m=1∑MΘm(tm−tm−1)
损失函数
损失函数由三部分组成
对每个分类的损失
- 分类损失
使用交叉熵
Lce=m=1∑M−ymlog(Θ^m)−(1−ym)log(1−Θ^m)
- 恢复损失
使用 Huber loss
Lrestore=ℓ(y^,y)
- 顺序先验正则化项
概率随着 m 增长单调减少
Lord=m=1∑M−1max(Θ^m+1−Θ^m,0)
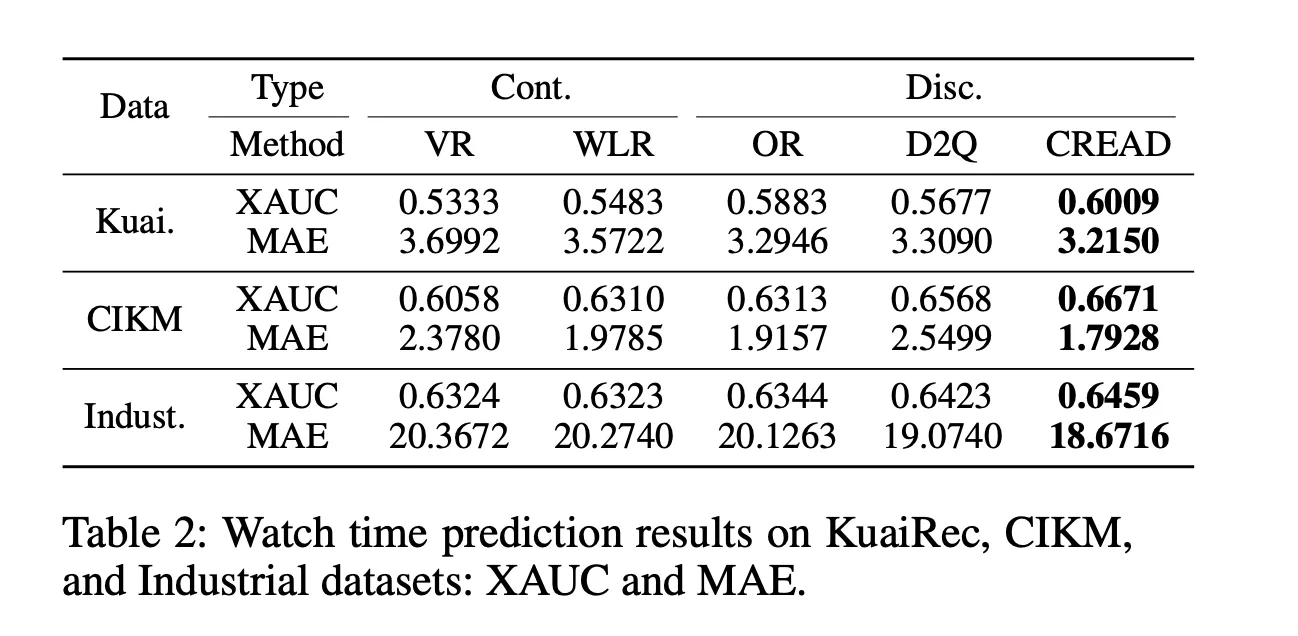
我感觉这篇文章看到这里已经可以了,它给出了一个新的预测观看时间的方式,数学理论也比较强。
文章后面则探讨了另外一个问题,也就是如何分桶。
自适应分桶
作者提出,对连续数据离散化会出现两种误差
-
学习误差
由于每个桶中的实例数量是有限的,因此 M 个分类器不可能无限准确。当我们增加桶的数量 M 时,每个桶中的实例数量就会减少,从而限制了分类性能。
-
恢复误差
离散化过程中使用求和代替积分,省略了每个桶中详细的概率密度,这也会引入误差。
 显而易见,这两个误差不能同时减少。为了减少学习误差,需要更大的桶宽度,从而导致更大的恢复误差。
传统上,我们有两种分类方法,等距分桶和等频分桶,但是这两种方案都不够好。
显而易见,这两个误差不能同时减少。为了减少学习误差,需要更大的桶宽度,从而导致更大的恢复误差。
传统上,我们有两种分类方法,等距分桶和等频分桶,但是这两种方案都不够好。
作者通过一系列的推导得出了
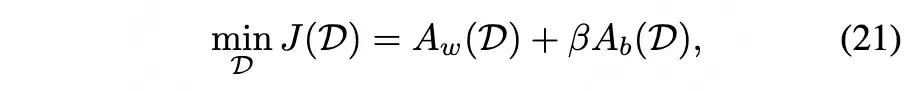
其中Aw, Ab分别表示学习误差和恢复误差:
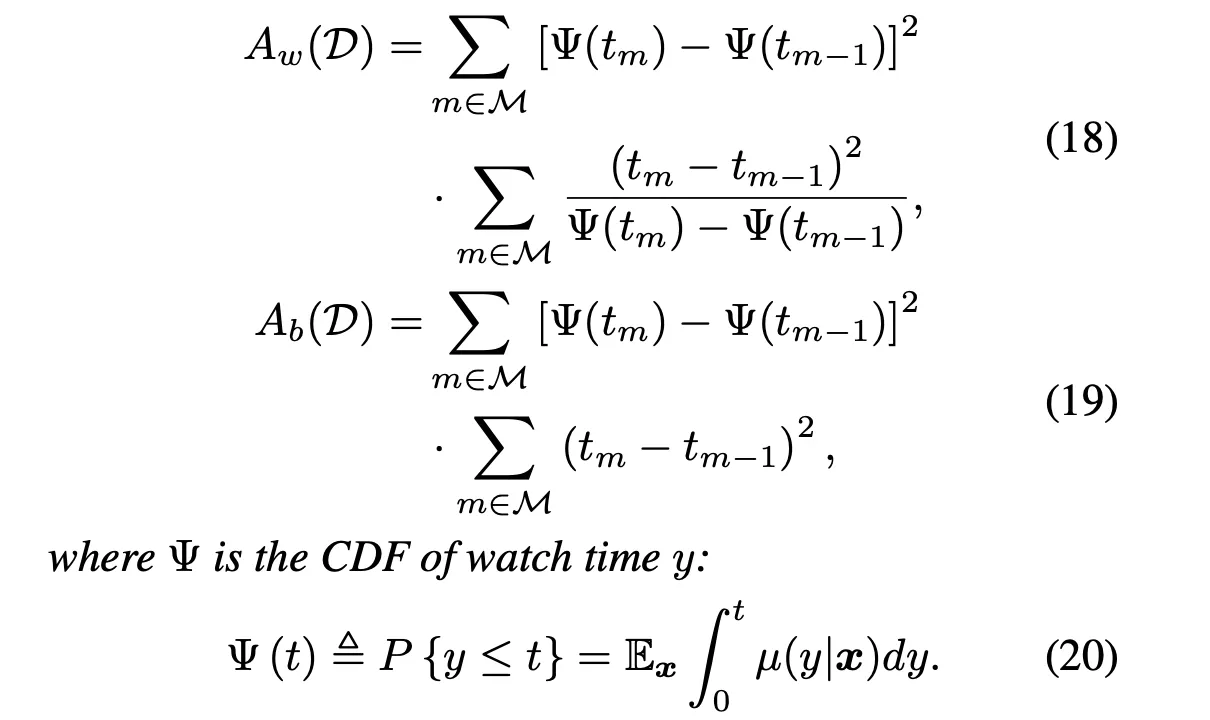
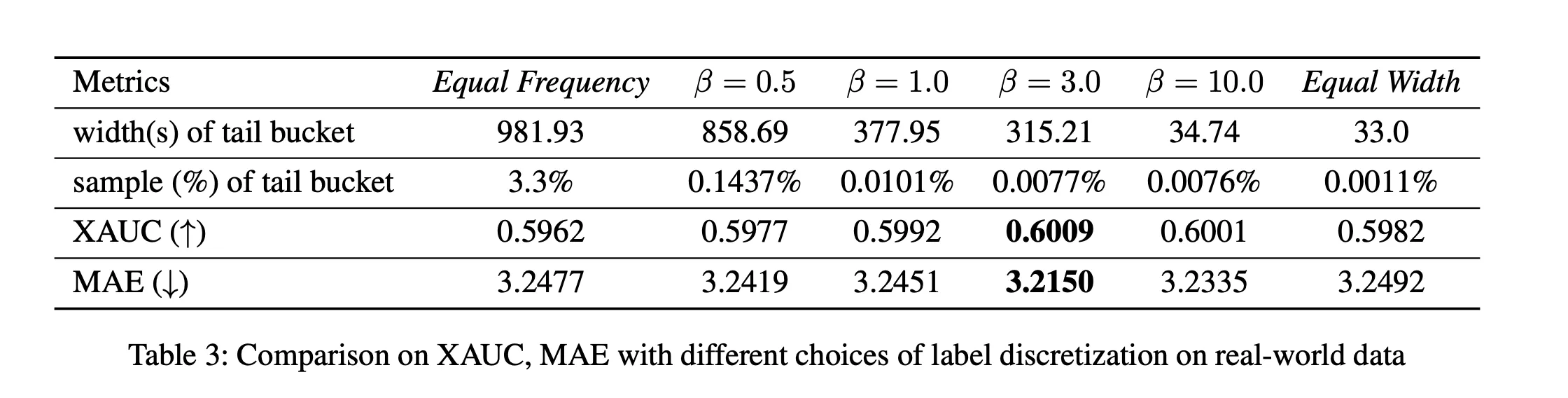
公式(21)中的 β 可以视为超参数,问题其实还没解决,因为公式(21)只是告诉我们如何计算tm对应的误差,并没有告诉我们如何设置tm才能最小化误差。
然后,作者介绍了一种启发式的方法(就是在等频和等距之间做 trade-off)。首先,正式表达等宽等频离散化方法,

这样我们可以将两个公式合并
tm=Ψ−1(γMm)
这里的 γ 是一个从[0,1]→[0,1]的校准函数,要满足γ(0)=0 , γ(1)=1。
当 γ(z)=Ψ(zTmax) 为等频分桶
当 γ(z)=z 为等距分桶
问题变成了如何寻找校准函数 γ来平衡等频分桶与等距分桶。本文使用了截断指数分布建模
γ(z,α)=(1−e−αz)/(1−e−α)
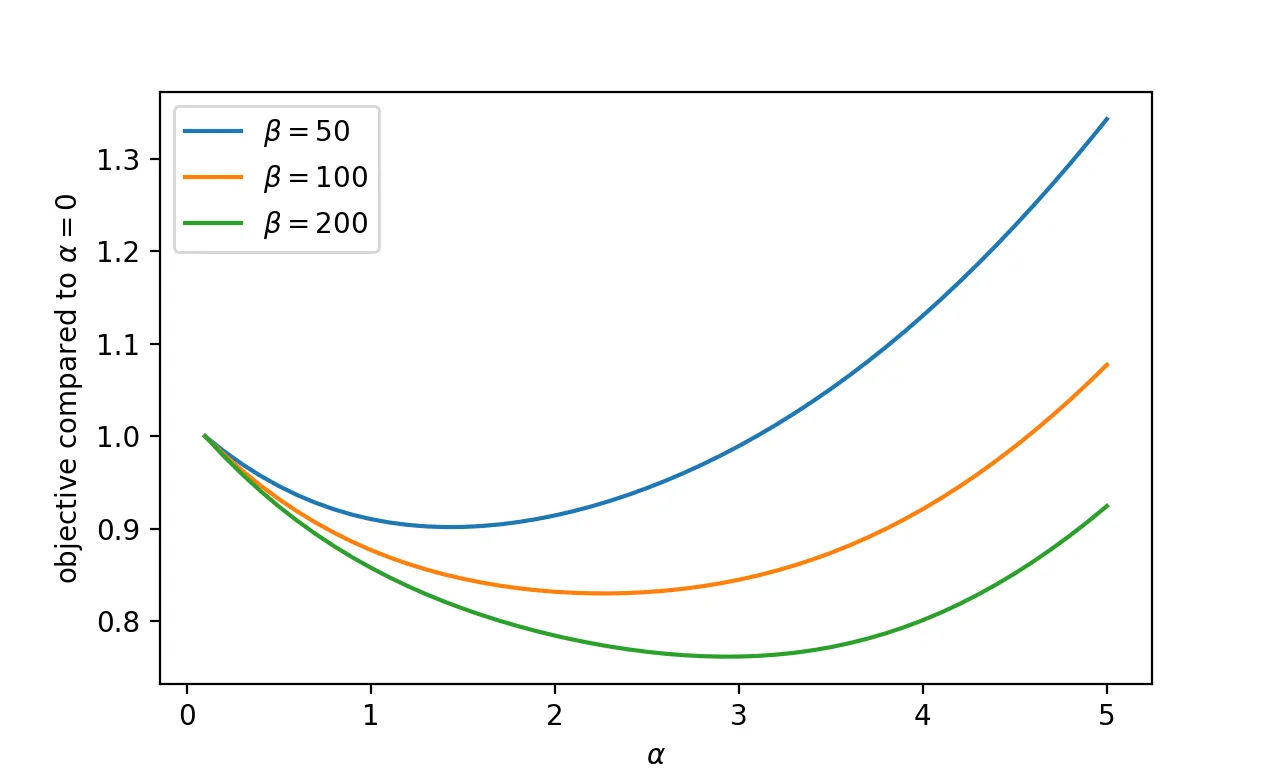
实验和超参数