AAAI'24 Kwai Watch Time Modeling: CREAD
This is an article from Kwai, mainly discussing two topics: modeling watch time and bucketing continuous features.
How to Model Watch Time?
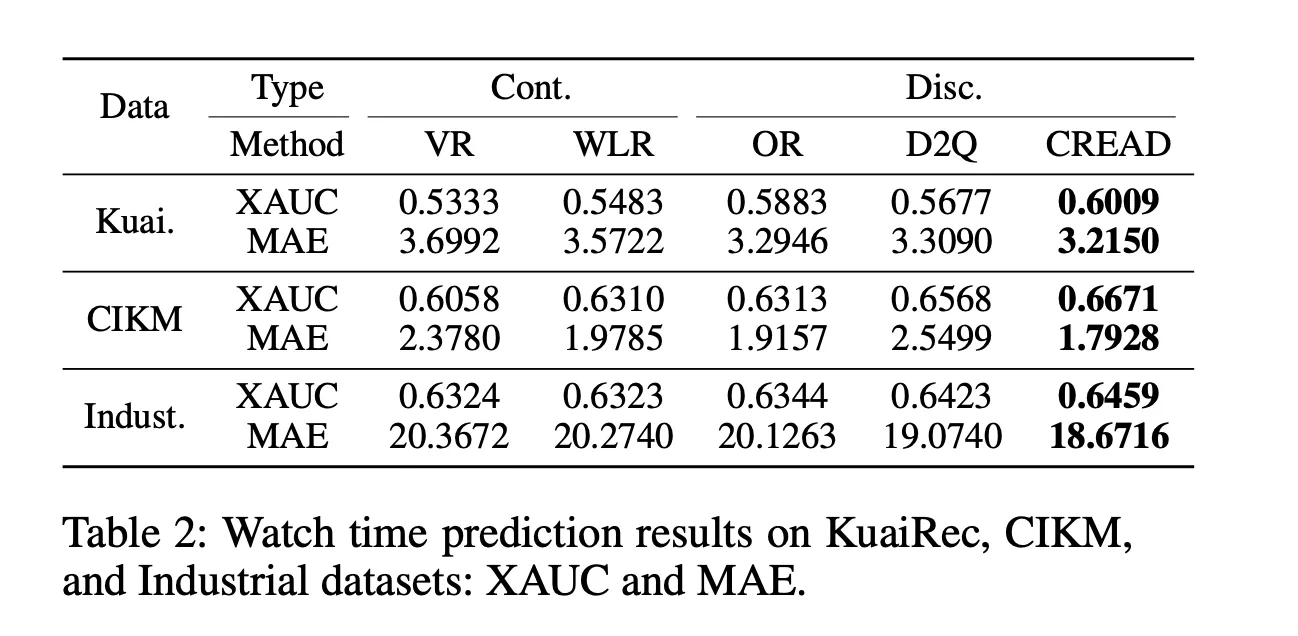
Kwai’s short video watch time distribution exhibits a similar pattern to our live streaming watch time, where data is extremely imbalanced and follows a typical long-tail distribution.

Usually, there are several methods for predicting watch time:
- Regression
- Weighted Logistic Regression
- Duration-Deconfounded Quantile
- Ordinal Regression
- Tree-based Progressive Regression
Can a simpler training task be proposed to predict watch time?
The solution proposed by this article is to use multiple classification tasks to approximate a regression task. The specific approach is similar to our method for handling continuous features, by discretizing watch time into multiple buckets and predicting whether the value falls into each bucket.

It is important to note that the discretization method here does not use one-hot encoding, but rather predicts the probability of exceeding a certain time threshold:
Derivation
The classification task becomes the following:
Recovery formula derivation:
Focusing on the second step:
Substitute into formula 1:
Combining these results gives:
Loss Function
The loss function consists of three parts:
-
Classification Loss Using cross-entropy:
-
Recovery Loss Using Huber loss:
-
Ordinal Prior Regularization Probability should monotonically decrease with increasing m:
I think this part of the article already provides a new way to predict watch time with strong mathematical foundations. The next part discusses how to perform bucketing.
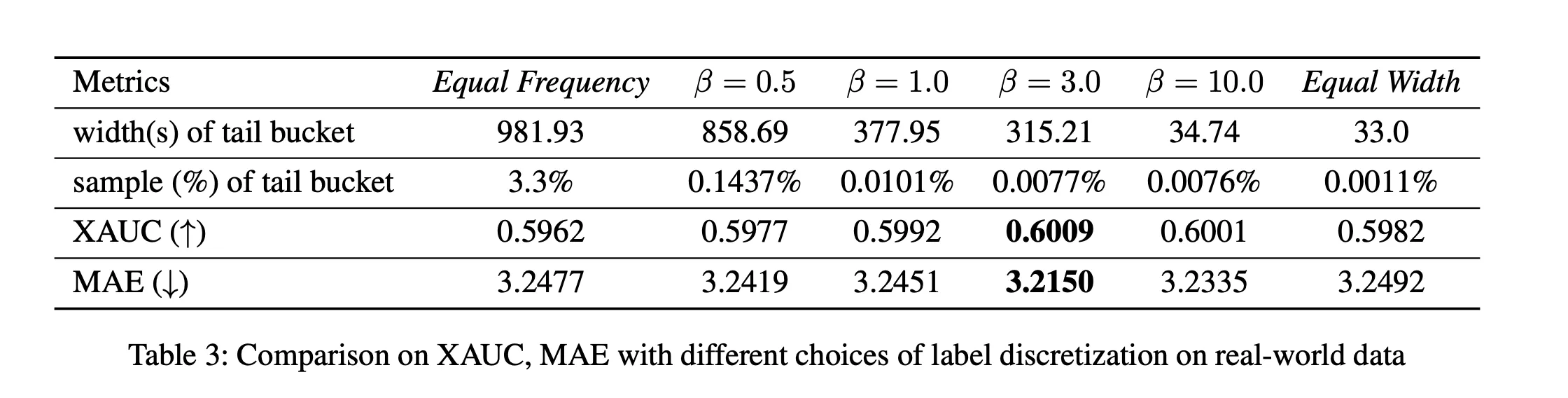
Adaptive Bucketing
The author points out that discretizing continuous data introduces two types of errors:
-
Learning Error Since the number of instances in each bucket is limited, the M classifiers cannot be infinitely accurate. Increasing the number of buckets M decreases the number of instances per bucket, thereby limiting classification performance.
-
Recovery Error During discretization, using summation instead of integration omits the detailed probability density within each bucket, which introduces error.

Clearly, these two errors cannot be reduced simultaneously. To reduce learning error, we need larger bucket widths, which increases recovery error.
Traditionally, there are two bucketing methods: equal-width bucketing and equal-frequency bucketing. However, both methods are suboptimal.
The author derives the following error formula:
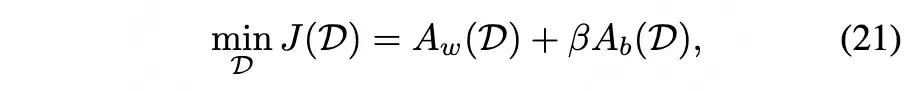
Where , represent learning error and recovery error respectively:
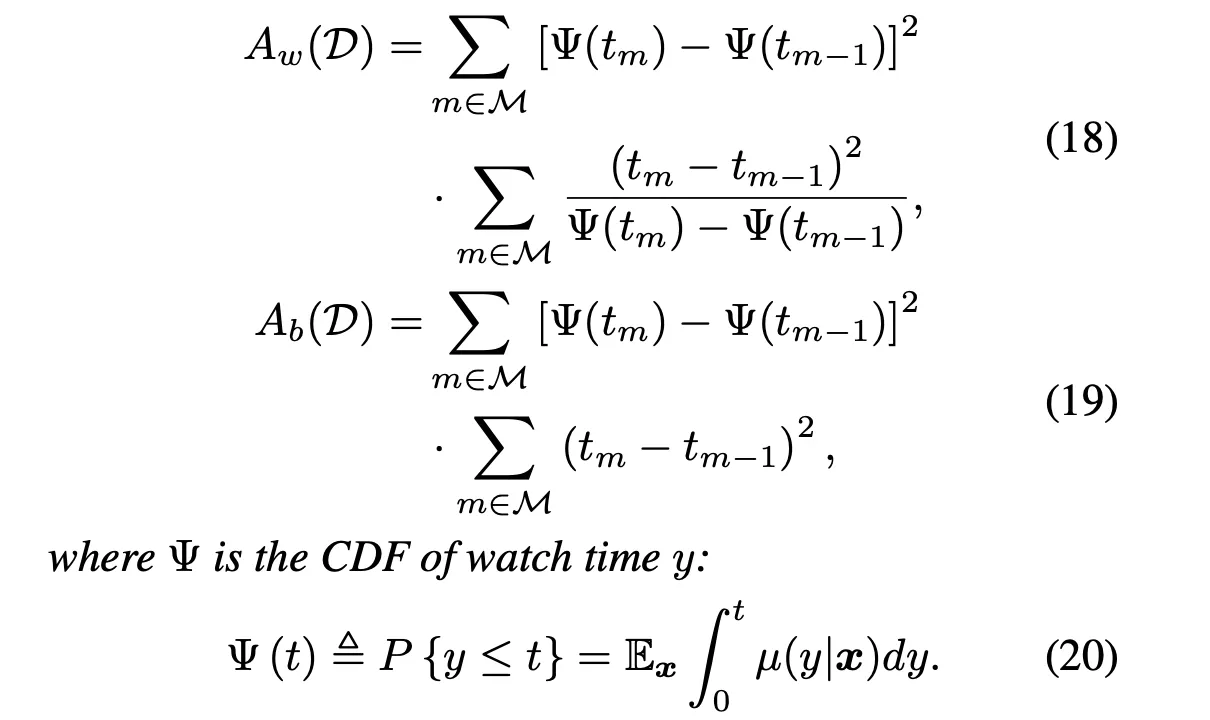
In Formula (21), can be considered a hyperparameter. The problem is not yet solved, because Formula (21) only tells us how to calculate the error corresponding to , but not how to set to minimize the error.
Then, the author introduces a heuristic method (balancing between equal-frequency and equal-width). First, the equal-width and equal-frequency discretization methods are formally expressed:
-
Equal-width definition:
This approach results in too few samples in the long-tail buckets, increasing learning error.
-
Equal-frequency definition:
This approach results in overly large intervals in the long-tail buckets, increasing recovery error.

Combining the two formulas gives:
Where is a calibration function from satisfying and .
- When , it is equal-frequency bucketing.
- When , it is equal-width bucketing.
The problem becomes finding a calibration function to balance equal-frequency and equal-width bucketing. The article uses a truncated exponential distribution model:
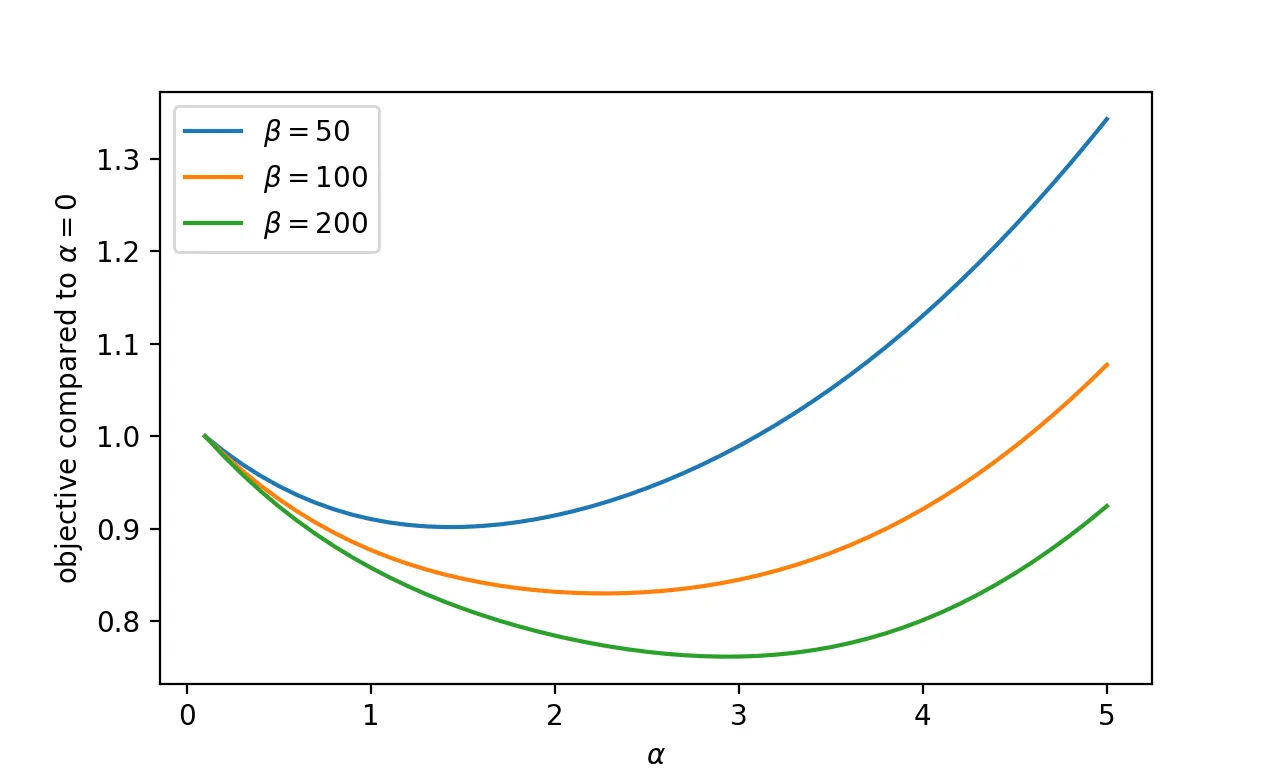
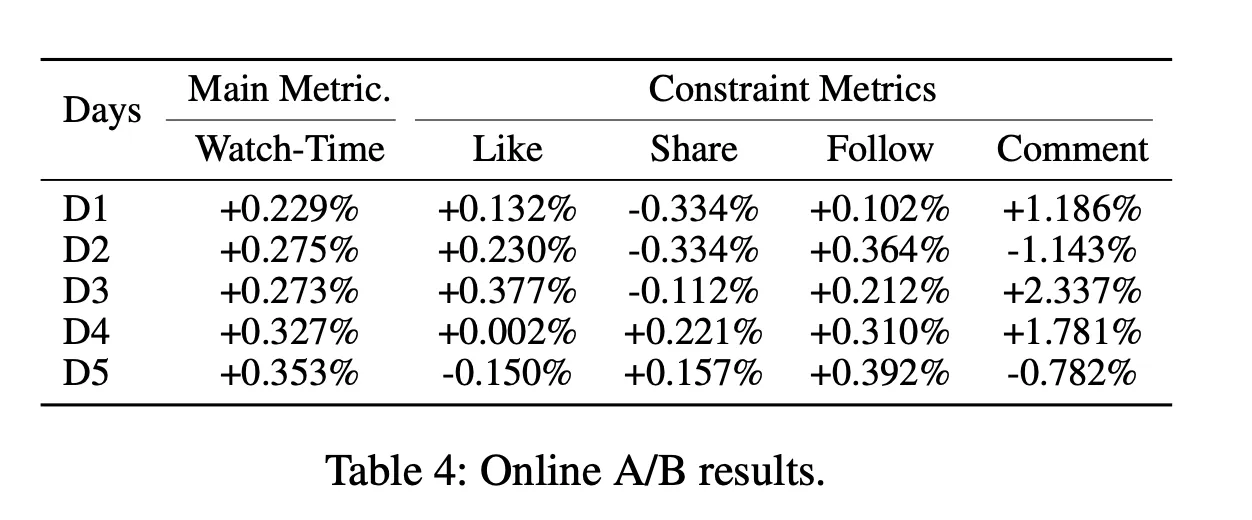
Experiments and Hyperparameters